Since the time that Isaac Newton first wrote his laws of motion and theory of gravity in mathematical form, science has made progress by using the two familiar methodologies, or “paradigms”, of experiment and theory.
With the dawn of digital computers, however, scientists were able to explore systems too complex to be analysed mathematically, or which involved extreme environments inaccessible to experiment (computer modelling of galaxy formation and climate change being two such examples).
Nobel laureate Ken Wilson called computation the “third paradigm” of scientific research, where computational science does not replace the paradigms of theory and experiment but requires scientists to learn new and different skills. These include knowledge of numerical methods, computer algorithms, programming languages and parallel computer architectures.
In 2001, John Taylor, then director general of research councils in the UK Office of Science and Technology, initiated the e-Science programme, which focused on managing the growing challenge of “data deluge” as well as the multidisciplinary collaborations needing to combine different datasets to explore new science.
Turing Award winner Jim Gray, of Microsoft Research, called such data-intensive science a "fourth paradigm" for research. Data-intensive science requires researchers to learn new skills in databases, data visualisation, data curation and, increasingly, advanced data analytics technologies such as machine learning.
The UK e-Science programme was funded for five years from 2001 to 2006. Ten years later, the challenges of managing the still-growing scientific data deluge are plain for all to see.
This “Big Scientific Data” revolution is being driven by the extreme volumes of data being generated by large facilities – such as the CERN Large Hadron Collider, Harwell’s Diamond Light Source and high throughput gene sequencers – and by new generations of satellites, wide-ranging sensor networks and by supercomputer simulations.
Open science begins with open access
The increasing importance of data and the need for more complex data analytical methods, along with the well-publicised problems in research reproducibility in certain fields, has led to a growing movement for “open science”.
Typically, the full text of a research paper will contain only a subset of the data used to derive the results, and may not specify precisely what software has been used for the analysis or for the simulation. The open science movement seeks to make science more reproducible by adding explicit links in the paper to the full datasets and to any software used. This movement has growing momentum in many countries around the world but here I will focus on the similarities and differences between two of the leading practitioners, the UK and the US.
Open science starts with open access – free access to the full text of research papers funded by government research agencies such as the National Science Foundation, Nasa and the National Institutes of Health in the US, and the Research Councils (soon to be united in UKRI) in the UK.
One of the most important starting points for the open access movement was the arXiv repository created by Paul Ginsparg at Los Alamos National Laboratory in New Mexico in 1991.
Instead of the common practice of exchanging paper “preprints” prior to refereeing and publication, Ginsparg took this into the digital world by setting up the arXiv repository to host digital versions – or “eprints” – of the full text of physics research papers.
Nowadays the arXiv repository is more than 20 years old and is hosted by the library at Cornell University where Ginsparg is a professor. More than 200,000 articles are downloaded from arXiv every week by about 400,000 users.
Ginsparg’s example inspired the US National Library of Medicine to set up the PubMed Central repository for voluntary author deposit of full text versions of NIH-funded research papers.
Deposit in PubMed Central is now mandatory for all NIH grant holders and the repository contains more than 3 million articles, with around 85,000 papers deposited each year. Although access is free, publishers can insist on a short embargo period of six or 12 months, after journal publication, and compliance with the NIH’s open success policy is about 90 per cent.
In the UK, Stevan Harnad was inspired by the arXiv example to write his famous “subversive proposal” in 1994, which called on researchers to make the full text of their research papers freely available over the internet.
With the support of Jisc, this idea evolved into the Green Open Access movement, which calls for the self-archiving of research papers by researchers in “institutional repositories”.
A key factor in the success of these university research repositories in the UK is the periodic evaluation process of university research.
For their research to be eligible for submission to the 2021 Research Excellence Framework exercise, researchers are required to have the full text of their papers deposited in “an institutional or subject repository”.
The lack of any such incentive for deposit by university researchers in the US is directly related to their relative lack of success in filling their repositories. This difference in emphasis between the US and the UK (i.e. research funding agency hosted repositories versus university-based institutional repositories) persists to this day.
The tipping point for open science
In my view, 2013 was the tipping point for the open science movement. In February of that year, the US Office of Science and Technology Policy issued a directive requiring the major federal funding agencies “to develop a plan to support increased public access to the results of research funded by the federal government”.
The results of research included digital data that the memorandum defined as “the digital recorded factual material commonly accepted in the scientific community as necessary to validate research findings, including data sets used to support scholarly publications”. This declaration was followed in May 2013 by the Global Research Council (consisting of abut 70 heads of research funding agencies) agreeing on an “Action Plan towards Open Access and high level Principles of Research Integrity”.
In June 2013, there were similar declarations from meetings of the G8 science ministers and the European Parliament. Finally, in August 2013, the University of California – one of the largest public research universities in the world – agreed a policy requiring all its 8,000 faculty to deposit full text copies of their research papers in the UC eScholarship repository, unless they specifically chose to opt out.
The US agencies have now all produced plans for increasing public access to their research and there are two solutions being adopted: NIH’s PubMed Central platform and the DOE PAGES platform developed by the Office of Scientific and Technical Information.
The DOE PAGES project is working with the publishing industry’s “Clearinghouse for the Open Research of the United States” (Chorus) consortium. Nasa has chosen to use NIH’s PubMed Central platform while the NSF and the DOD are using DOE’s PAGES.
These agencies fund much of the research published each year in the US. The approximate numbers of papers published by each agency each year are: NIH 85,000; Nasa 7,000; DOE 26,000; NSF 42,000; DOD 15,000.
These research papers are all required to be freely available after a possible embargo period and the global impact of this for the open access movement cannot be overemphasised.
Metadata, data management plans and all that
In the UK, the Digital Curation Centre was set up by Jisc and the e-Science Programme in 2004. The original call to establish the DCC described its function as “to provide a national focus for research into curation issues and expertise in the processes of digital archiving, preservation and management. Particular emphasis will be placed on the needs of users of the Centre's outputs”.
One of the DCC’s roles was to educate the research community about the importance of research data management and the DCC produced some of the earliest guidelines for how to develop “Data Management Plans”. In both the US and the UK, collaboration and sharing of data is increasingly expected of researchers by the research funding agencies. In addition, the agencies on both sides of the Atlantic now demand that researchers include a data management plan for the data generated by their research proposals.
In the US, the research funding agencies now all have plans to capture research data, assign digital object identifiers (DOIs) to the datasets, and link the data to the relevant research papers. In the UK, again it is the institutional repositories, together with subject data repositories such as the Natural Environment Research Council’s Centre for Environmental Data Analytics, that are taking the lead. The different research councils do not yet have a completely common policy for research data management and the policy of the Engineering and Physical Sciences Research Council is the most explicit in spelling out the obligations on universities:
“Research organisations will ensure that EPSRC-funded research data is securely preserved for a minimum of 10 years from the date that any researcher ‘privileged access’ period expires or, if others have accessed the data, from the last date on which access to the data was requested by a third party…”
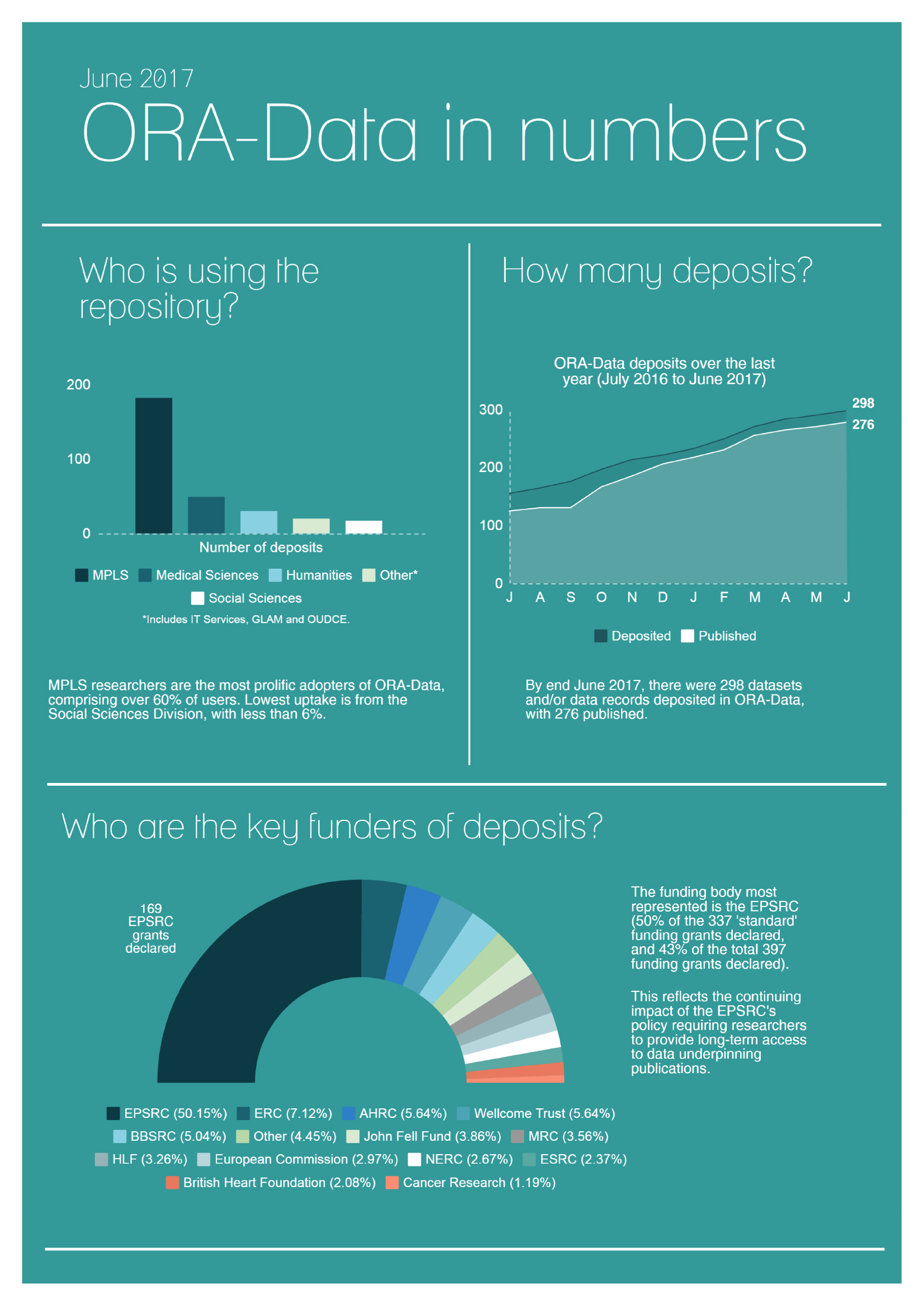
The policy also states that: “Data that have not attracted any interest for more than 10 years are not expected to be retained”. The effect of this policy can be seen from the statistics of the Oxford Research Archive for Data (below), which shows the increase in data deposits over the last 12 months and which Research Councils have funded the research.
Onwards to open science
My conclusion is that, in both the UK and US, definite progress is being made towards the goal of open science. However, changing cultures towards the new reality of data-intensive science sometimes seems painfully slow.
Jim Gray had a vision that all scientific data would be made available online and linked to the corresponding open access journal articles. His inspiration was the US National Library of Medicine at the National Institutes of Health, which, in addition to providing the curated PubMed Central repository for the full text of NIH-funded research papers, also provides links to a large set of curated databases such as GenBank and PubChem.
Gray believed, as I do, that if we can populate these institutional, funding agency and subject repositories with open access research papers linked to the corresponding datasets, this would lead to a huge increase in scientific productivity.
Given the environmental and medical challenges facing the world, open science is needed as a matter of urgency.
Tony Hey is chief data scientist at the UK’s Science and Technology Facilities Council.
This article was commissioned by Times Higher Education in partnership with Jisc as part of the Jisc Futures series. Jisc is the UK’s expert body for digital technology and resources in higher education, further education, skills and research.
Register to continue
Why register?
- Registration is free and only takes a moment
- Once registered, you can read 3 articles a month
- Sign up for our newsletter
Subscribe
Or subscribe for unlimited access to:
- Unlimited access to news, views, insights & reviews
- Digital editions
- Digital access to THE’s university and college rankings analysis
Already registered or a current subscriber?